
Teaching AI to reason: this year's most important story

Most people think of AI as a pattern-matching chatbot – good at writing emails, terrible at real thinking.
They've missed something huge.
In 2024, while many declared AI was reaching a plateau, it was actually entering a new paradigm: learning to reason using reinforcement learning.
This approach isn’t limited by data, so could deliver beyond-human capabilities in coding and scientific reasoning within two years.
Here's a simple introduction to how it works, and why it's the most important development that most people have missed.
The new paradigm: reinforcement learning
People sometimes say “chatGPT is just next token prediction on the internet”. But that’s never been quite true.
Raw next token prediction produces outputs that are regularly crazy.
GPT only became useful with the addition of what’s called “reinforcement learning from human feedback” (RLHF):
The model produces outputs
Humans rate those outputs for helpfulness
The model is adjusted in a way expected to get a higher rating
A model that’s under RLHF hasn’t been trained only to predict next tokens, it’s been trained to produce whatever output is most helpful to human raters.
Think of the initial large language model (LLM) as containing a foundation of knowledge and concepts. Reinforcement learning is what enables that structure to be turned to a specific end.
Now AI companies are using reinforcement learning in a powerful new way – training models to reason step-by-step:
Show the model a problem like a math puzzle.
Ask it to produce a chain of reasoning to solve the problem (“chain of thought”).1
If the answer is correct, adjust the model to be more like that (“reinforcement”).2
Repeat thousands of times.
Before 2023 this didn’t seem to work. If each step of reasoning is too unreliable, then the chains quickly go wrong. Without getting close to correct answers, there was nothing to reinforce.
But now it’s started to work very well…
Reasoning models breakthroughs
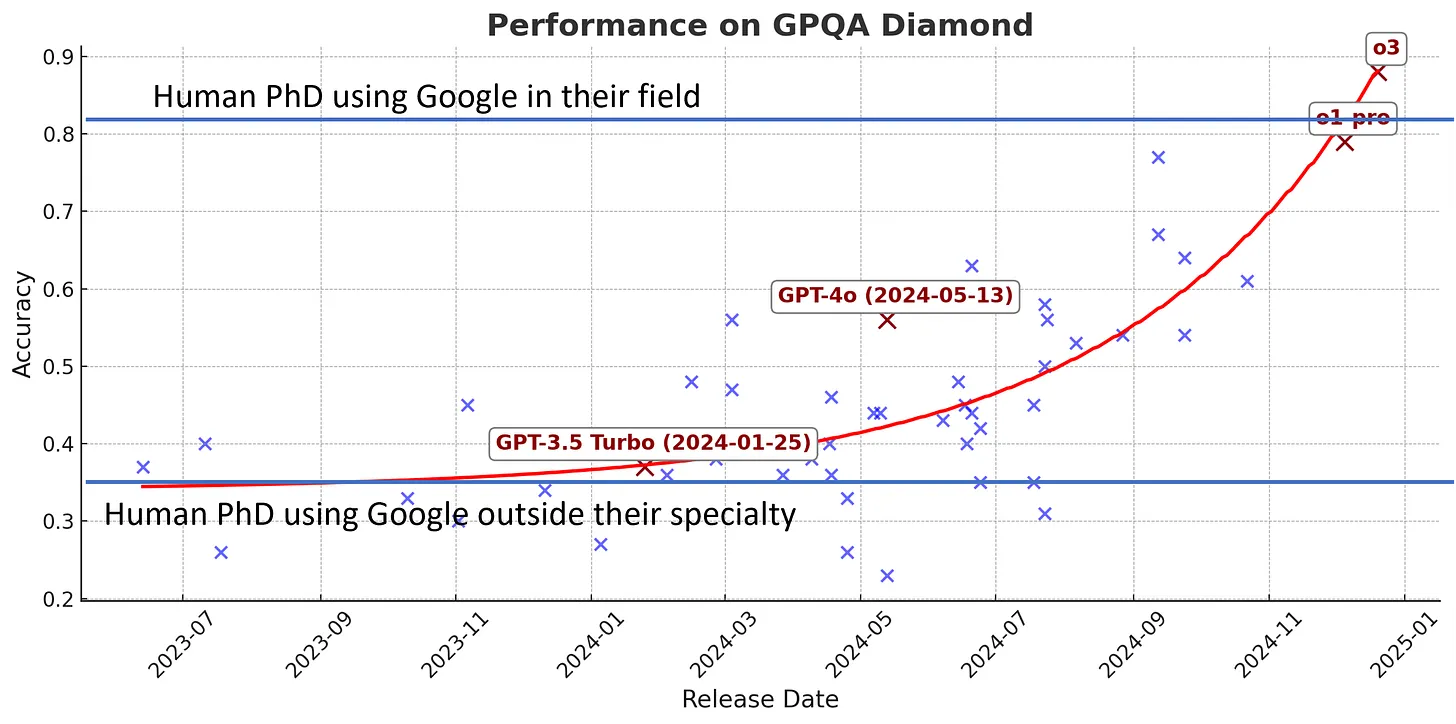
Consider GQPA –– a set of new scientific questions designed so that people with PhDs in the field can mostly answer them, but non-experts can’t, even with 30min access to Google. It contains questions like this:

I did a masters level course in theoretical physics, and I have no clue.
In mid 2023, GPT-4 was barley better at random guessing on this benchmark. In other words, it could reason through high school level science problems, but it couldn’t reason through graduate level ones.
Then came GPT-o1, built by OpenAI using reinforcement learning on top of GPT-4o base model.3
Suddenly it could get 70% of questions right – making it about equal to PhDs in the relevant field.

Most people are also not regularly answering PhD-level science questions, so have simply haven’t noticed recent progress.
Most criticisms of AI are based on the free models, and those don’t include o1, which can typically already do the things people say AI can’t do.
And o1 was just the beginning.
A new rate of progress?
At the start of a new paradigm, it’s possible to get gains especially quickly. Just three months later in December, OpenAI released results from GPT-o3 (the second version, but named ‘3’ because o2 is taken by a telecom company).
GPT-o3 is probably GPT-o1 but with even more reinforcement learning, and perhaps the addition of “tree search” – generating 10 or 100 solutions, and picking the one that appears most (yes advancing modern AI really is that simple).4
o3 surpassed human experts on the GPQA benchmark.
(Chart from Ethan Mollick.)
Earlier LLMs were good at writing but bad at math and rigorous thinking. Reinforcement learning flips this pattern – it’s most useful in domains with verifiable answers, like coding, data analysis and science.
GPT-o3 is much better in all of these domains than its base model.
For example, SWE bench verified is a benchmark of real-world software engineering problems from github that typically take under an hour.
GPT-4 could, when put into an agent architecture, solve about 20%.
GPT-o3 could solve over 70%.
This means o3 is basically as good as professional software engineers at completing these discrete tasks.

On competition coding problems, o3 would have ranked within the top 200 human competitors in the world.
The progress in mathematics is maybe even more impressive. On high school competition math questions, o3 leapt up another 20% compared to o1 – a huge gain that might have taken a year ordinarily. Most math benchmarks have now been saturated.
In response, Epoch AI created Frontier Math – a benchmark of insanely hard mathematical problems. Field’s Medalist Terrance Tao said the most difficult 25% of questions were “Extremely challenging”, and that you’d typically need an expert in that branch of mathematics to solve them.
Previous models, including GPT-o1, could hardly solve any of these questions.5 OpenAI claimed that GPT-o3 could solve 25%.6
Reasoning models can check their own thinking, so are less likely to hallucinate or make weird mistakes.
AI researcher Francois Challot was a proponent of the common criticism that LLMs are “just sophisticated search” rather than “real reasoning”. He developed the ARC-AGI benchmark, a series of pattern recognition puzzles a bit like an IQ test, which were relatively easy for humans but hard for LLMs. That is, until o3.7
All these results went entirely unreported in the media. In fact, on the same day as the o3 results, the front page of the Wall Street Journal looked like this:

The WSJ article is about GPT-5, but that misses the point. Even without GPT-5, AI can improve rapidly with reinforcement learning alone.
Why this is just the beginning
In January 2025, DeepSeek replicated many of o1’s results. This got a lot more attention because it was Chinese.
But the bigger story is that reinforcement learning works.
A key thing we learned from Deepseek that even basically the simplest version of it works.8 This suggests there’s a huge amount more to try.
(It’s also why Anthropic and Google also have already been able to train models just as good; in fact Google’s Gemini 2.0 Flash is even cheaper and better than DeepSeek, and was released earlier.)
DeepSeek also reveals its entire chain of reasoning to the user. From this, we can see the sophistication and surprisingly human quality of its reasoning: it’ll reflect on its answers, backtrack when wrong, consider multiple hypotheses, have insights and so on.

OpenAI researcher Sabastian Bubeck noted:
No tactic was given to the model. Everything is emergent. Everything is learned through reinforcement learning. This is insane.
We’re also seeing some generalisation. Nathan Labenz claims GPT-o1 is better at legal reasoning, despite not being trained directly on legal problems.
And it will be possible to apply reinforcement learning to other domains, like business strategy or writing tweets, it’s just the reinforcement signals will be noisier, so it will take longer.
How far can this go?
The compute for the reinforcement learning stage of training DeepSeek likely only cost about $1m.
If it keeps working, OpenAI, Anthropic and Google could now spend $1 billion on the same process, a 1000x scale up.9
One reason it’s possible to scale up 1000x is that the models now generate their own data.
This might sound circular, or likely to result in “model collapse”, but it’s not.
You can ask GPT-o1 to solve 100,000 math problems, then take only the correct solutions, and use them to train the next model.
Because the solutions can be formally verified, you’ve generated more examples of genuinely good reasoning.
In fact, this data is much higher quality than internet data, because it contains the whole chain of reasoning, and is known to be correct (not something the text on the internet is famous for).
This creates a potential flywheel:
Model solves problems.
Use the solutions to train the next model.10
The better model can solve even harder problems.
That generates more solutions
Repeat.
If the models are already able to do PhD-level reasoning, the next stage would be to push into researcher-level reasoning, then perhaps into insights humans haven’t had yet.
Two more accelerants
On top of that, reasoning models unlock several other ways to improve AI.
First, if you ask them to generate longer chains of reasoning for each question, they produce better answers.
That didn’t use to work because mistakes would compound too quickly, but now OpenAI showed that you can have GPT-o1 think 100-times longer than normal, and get linear increases in accuracy on coding problems.
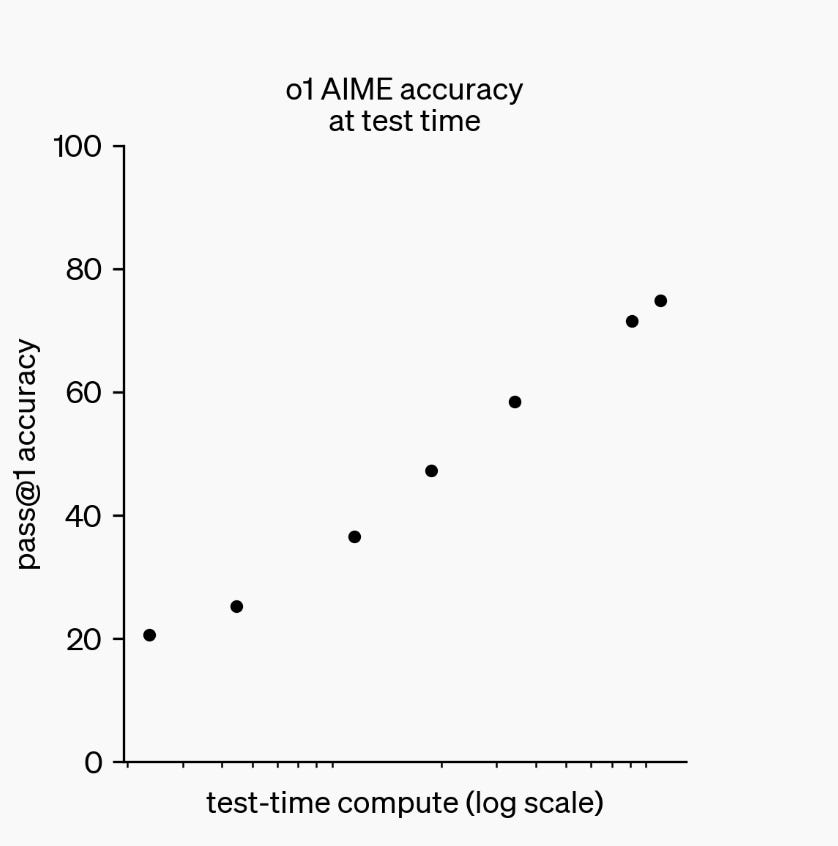
As reasoning models become more reliable, they will be able to think for longer and longer. Just like a human, this lets them solve more difficult problems even without additional intelligence.
This can “pull forward” more advanced capabilities on especially high-value tasks.
Suppose GPT-o7 can answer a question for $1 in 2028. Instead in 2026 you’ll be able to pay GPT-o5 $100,000 to think 100,000 times longer, and generate the same answer.11
That’s too expensive for most users, but still a bargain for important scientific or engineering questions.
Second, reasoning models could make AI agents work a lot better. Agents are systems that can semi-autonomously complete projects over several days, and are now the top priority of the frontier companies.
Reasoning models make agents more capable because:
They’re better at planning towards goals.
They can check their work, improving reliability, which is a huge bottleneck.
We’re starting to see signs of how reasoning models, thinking for longer, and agents all mutually support each other.
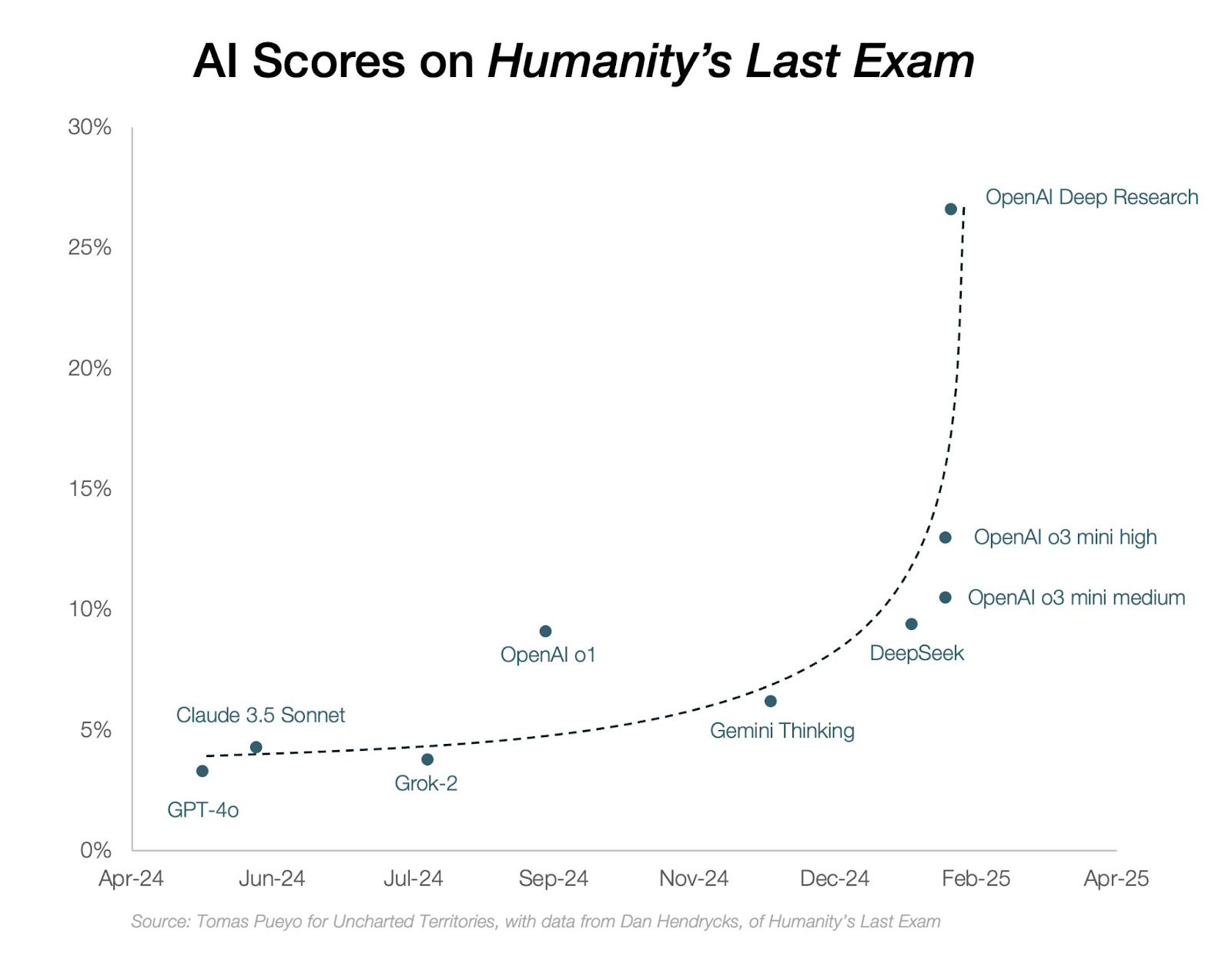
Humanity’s Last Exam is a collection of 3,000 questions from 100 fields designed to be at the frontier of human knowledge. The full questions are not available on the internet, but include things like:

GPT-4o could answer 3%, and even GPT-o1 could only answer 9%.
In Feb 2025, OpenAI released a research agent, DeepResearch, which can browse through hundreds of web pages and pdfs, do data analysis, and synthesise the results. It scored 27%.12
All this probably explains the even-more-optimistic-than-usual statements from the AI company leaders that started in December.
In November 2024 the OpenAI’s CEO Sam Altman said:
I can see a path where the work we are doing just keeps compounding and the rate of progress we've made over the last three years continues for the next three or six or nine.
Just a month later after the o3 results, that had morphed to:
We are now confident we know how to build AGI as we have traditionally understood it...We are beginning to turn our aim beyond that, to superintelligence in the true sense of the word.
In January 2025, Anthropic’s CEO Dario Amodei told CNBC:
I’m more confident than I’ve ever been that we’re close to powerful capabilities…A country of genius in a data center…that’s what I think we’re quite likely to get in the next 2-3 years
Even Google DeepMind's more conservative CEO Demis Hassabis moved from "maybe 10 years away" to "probably 3-5 years."
They’re probably still overoptimistic (as they’ve been in the past), but reinforcement learning plus agents could be a straight shot to AGI in two years.
Most likely, AGI in the sense of an AI that can do most knowledge work tasks better than most humans13 will take longer due to a long tail of real world bottlenecks in reliability, perception, lack of physical presence etc. (Their deployment will also be slowed by compute constraints, inertia and regulation.)
But definitions aside, our default expectation should be for further dramatic progress in capabilities.
In particular, progress could be even faster than the recent trend for domains especially suited to reinforcement learning, like science, coding and math.
It seems quite likely that within two years we have AIs agents with beyond-human abilities in several-hour coding tasks, and that can answer researcher-level math and science questions.
We may see AI starting to figure out problems that have so far eluded humans.
That would already be a huge deal – enough to accelerate technology and scientific research.
But even more importantly, it might take us to AI that can speed up AI research.
The key thing to watch: AI doing AI research
The domains where reinforcement learning excels are exactly those most useful to advancing AI itself.
AI research is:
Purely virtual (experiments can be done in code)
Has measurable outcomes.
Bottlenecked by software engineering
METR has developed a benchmark of difficult AI research engineering problems – the kind of things that real AI researchers tackle daily, like fine tune a model, or predict the result of an experiment.
When put into a simple agent, GPT-o1 and Claude 3.5 Sonnet are already better than human experts when given 2 hours.

Human experts still overtake over longer timeframes (4+ hours), but AI is getting better at longer and longer horizons.
GPT-4o was better when given only 30 minutes – the leap from that to GPT-o1 being better over two hours was a lot faster than many expected.
And we haven’t even seen the results for o3.
Now consider what might happen the next two years:
GPT-4o replaced with GPT-5 as the base model
GPT-5 trained to reason with up to ~1000x more reinforcement learning
This model put into a better agent scaffolding
A continuation of trend could easily bring us to a model that’s better at human experts at AI engineering over 8h or 16h.
That would be quite close to having mid-level engineering employees on demand.
We don’t know how much that would speed up progress, but a modest speed-up could still bring the next advance sooner.
Historical returns to investment in AI research suggest there’s roughly a 50% chance that starts a positive feedback loop in algorithmic progress.
That would continue until diminishing returns are hit, and could take us from “AI engineering agent” to “full AGI” and onto “superintelligence” within a couple of years. Or at a lower bound, billions of science & coding agents thinking 100x human speed.
Even without a pure software feedback loop, we could still see positive feedback loops in chip design: more AI → more funding for chips → more AI capability → repeat. We could easily enter a world where the number of AI agents increases tenfold yearly.
AI researcher agents could be turned to robotics research, relieving one of the main remaining bottlenecks, and then spread into other forms of R&D.
Eventually we’ll see positive feedback loops at the level of the economy as a whole.
This would be the most important scientific, economic, social and general fate-of-the-world development in the world right now.
I find it extremely surreal how maybe 10,000 technologists on twitter have figured this out, but most of the world continues as if nothing is happening.
Here are some thoughts on what it might mean for your own life. Subscribe for upcoming articles on how to help the world navigate this transition.
It does this by producing one token of reasoning, then feeding that token back into the model, and asking it to predict what next token would most make sense in the line of reasoning given the previous one, and so on. It’s called “chain of thought” or CoT.
OpenAI probably also does reinforcement learning on each step of reasoning too.
They probably also did a couple of other steps, like fine-tuning the base model on a data set of reasoning examples. They probably also do positive reinforcement based on each step in the reasoning, rather than just the final answer.
Listen to Nathan Labenz for why it’s likely doing tree search.
There are other ways to do tree search - majority voting is just one example.
In Epoch’s testing, the best model could answer 2%. If the labs had done their own testing, this might have been a bit higher.
There was some controversy about the result because OpenAI has some involvement in creating the benchmark. However, I expect the basic point that GPT-o3 performed much better than previous models is still correct.
It’s true that o3 cost more than a human to do these tasks, especially in the high compute mode, but the cost of inference is falling 3-10x per year, and even the low compute version of the model shows significant gains.
GPT-o1 is probably doing a few extra steps compared to Deepseek, such as reinforcement learning on each step of reasoning, rather than just the final answer. However, every technique seems to work.
This is easily affordable given money they’ve already raised, and is still cheap compared to training GPT-6. In terms of effective compute, the scale up would be even larger, due to increasing chip and algorithmic efficiencies. Though, if it were applied to larger models, the compute per forward pass would go up.
The Deepseek paper shows you may be able to make this even easier by taking the old model and distilling it into a much smaller model. This enables you to get similar performance but with much less compute required to run it. That then enables you to create the next round of data more cheaply. And it enables you to iterate faster, because smaller models are quicker to train.
In addition, the trend of 10x increases in algorithmic efficiency every two years mean that your ability to produce synthetic data increases 10x every two years. So even if it initially takes a lot of compute, that’ll rapidly change.
In 2023, Epoch estimated you should be able to have a model think 100,000 longer, and get gains in performance equivalent to what you’d get from a model that was trained on 1000x times more compute – roughly one generation ahead.
This rate of progress probably won’t be sustained because the questions were designed to be things that previous models couldn’t answer. So typically the first new type of model to address a new benchmark will show a bump in performance. But it’s still faster than expected.
In terms of price performance. See more on defining AGI in this paper by DeepMind.
It drives me insane how very few people can extrapolate these scenarios based on what is happening today.
I have been trying to walk my social circle through these scenarios and I get either some denial pushback or outright dismissiveness. I don't think it comes from a place of pure denial, its just more they would rather not think about it.
It is really giving me Late February - Early March 2020 vibes.
Important update on this post: https://substack.com/@benjamintodd/note/c-111372048?utm_source=activity_item