
The most important graph in AI right now: time horizon

This week, METR released a wild graph: a plot of the length of tasks AI can do over time, which when projected forward, appears to get us to ‘AGI’ by 2028.
It’s perhaps the most important single piece of evidence for short timelines we have right now.
It also explains why – despite AI being ‘smart’ – we haven’t yet seen widespread automation. But more importantly, it reveals why that might be about to change.
Here’s a short explanation of how the graph was made, and why everyone in AI has been talking about it.
The crucial threshold: AI that can do AI research
We reach a crucial inflection point when AI can do AI research.
If we don’t reach that point by 2030, then AI progress will slow.
If we do, then AI progress will continue, or even accelerate, and the ‘intelligence explosion’ could start.
How close are we to this threshold?
To answer that question, the METR developed RE-Bench: a benchmark of seven difficult AI research engineering tasks.
These aren’t toy problems, they’re designed to be as close to difficult, real-world AI research engineering tasks as possible, and include things like fine-tuning models or predicting experimental results.
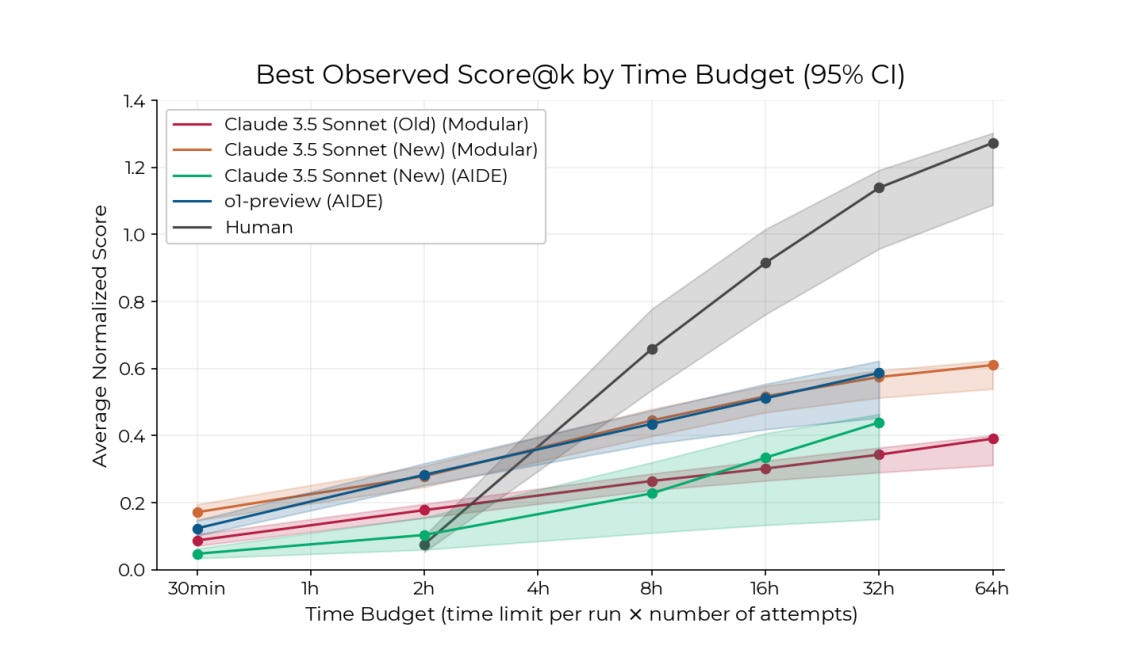
Near the end of 2024, an AI agent powered by o1 and Claude 3.5 Sonnet was able to do these tasks better than human experts when given two hours to work on them.
This result was the one most likely to cause forecasters I follow to shorten their timelines last year.
But after those two hours, the AI models hit a plateau, while humans continued to improve. So as of late 2024, human experts were still clearly better than leading AI models, so long as they were given enough time.
The crucial trend
Here’s where it gets even more interesting. Six months earlier, GPT-4o was only able to do tasks which took humans about 30 minutes.
That’s a dramatic improvement in just half a year. What happens if we look at this trend more broadly?
METR have just released an analysis doing exactly that.
They created a broader benchmark including:
The original RE-Bench tasks
~100 real-world software engineering, cybersecurity and general reasoning challenges (HCAST).
Some quick, easier computer use tasks
They categorized these tasks by how long it takes humans to complete them. Then, for each AI model, they determined the longest task length at which it could successfully complete more than half the tasks.
The results reveal the most important graph for forecasting AI right now:

In short:
GPT-2 could mostly handle computer use tasks that take humans a few seconds
GPT-4 could manage tasks that take humans a few minutes
o1 can now handle tasks that take humans just under an hour
The main graph is on a log scale, but here’s how it looks if plotted on a linear axis:

If this trend continues, AI models will be able to handle multi-week tasks by late 2028 with 50% reliability (and multi-day tasks with close to 100% reliability).
Two years after that, they’ll be able to tackle half of multi-month projects.
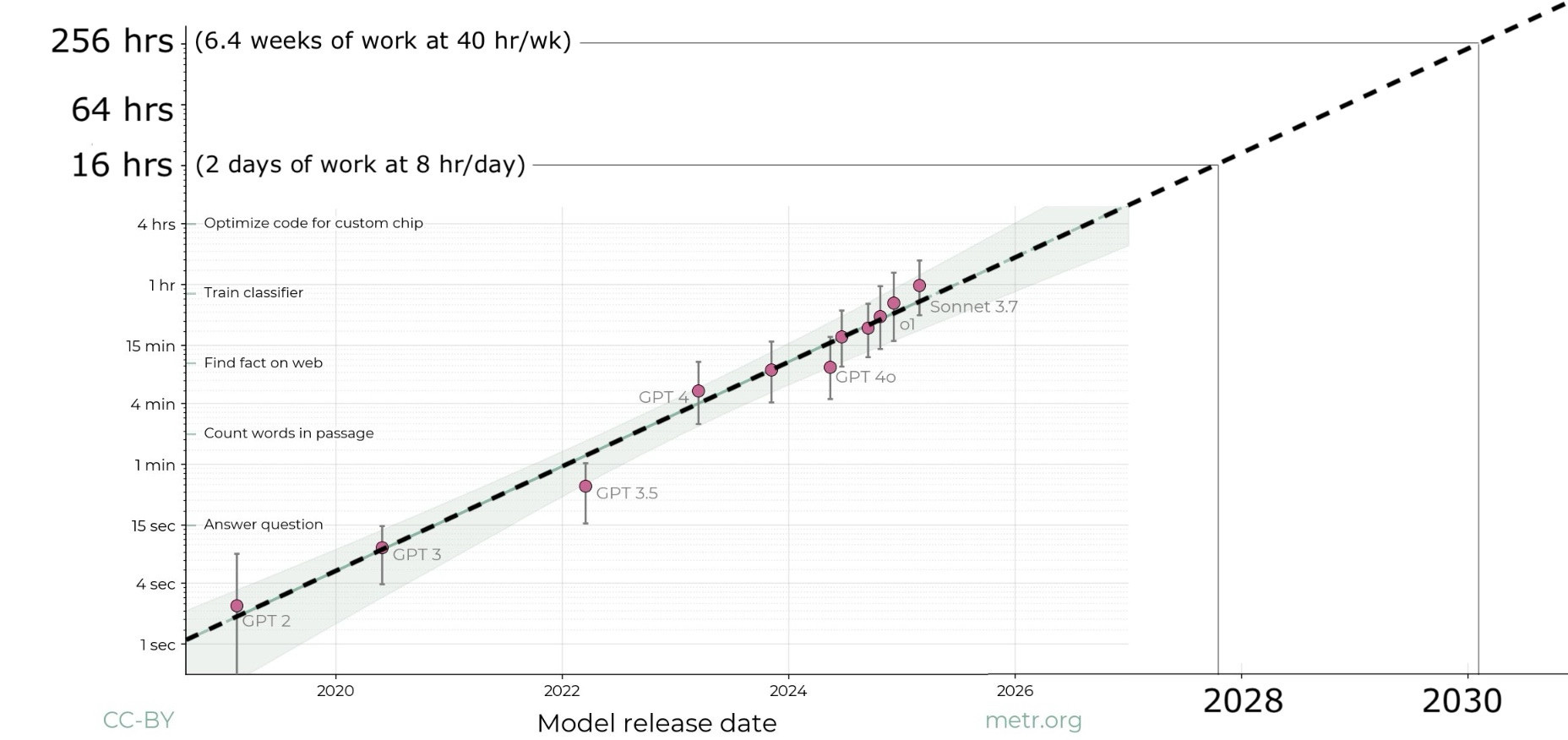
The trend line is for the last six years, but the trend over the last year is actually even faster, perhaps reflecting the new reasoning models paradigm.
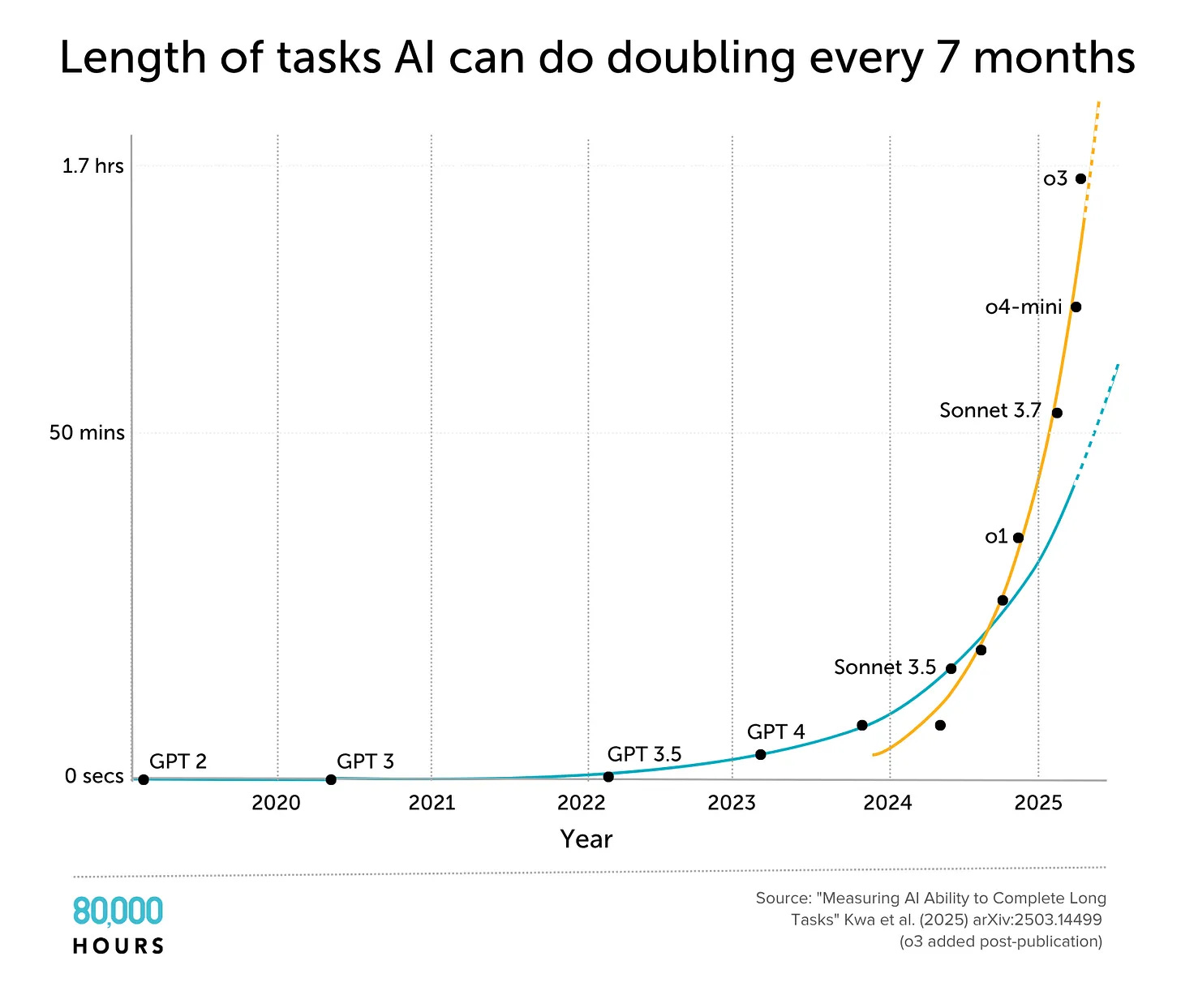
Update: Since this post was released, o3 was tested, and it appears to be on the even faster trend. Here’s a graph with a linear scale:
Why this matters
AI models today are already very ‘smart’ in that they can answer discrete science and math questions better than even many human experts.
Yet we haven't seen widespread automation of knowledge work. Why?
Because most valuable work isn't composed of well-defined, hour-long tasks.
Real jobs usually involve ill-defined, high-context, long-horizon work:
Figuring out what needs to be done in the first place
Coordinating with team members
Working on projects that span days or weeks
Even something seemingly simple like getting a shelf installed involves planning where to put it, choosing a design that fits the room, hiring a contractor, agreeing on a price, and checking that the work was done correctly. Current AI, even if given all the relevant inputs, is very bad at all of these tasks.
But the time horizon graph suggests that's about to change.
If AI models reach the point they can complete multi-week tasks autonomously, they'll function more like true "digital workers" that you can manage similar to human employees.
A chatbot can only make an individual worker marginally more effective, but if human managers can instantly hire hundreds of digital workers, the economic applications of AI will expand dramatically.
With a little oversight, these AIs will probably be able to tackle difficult multi-year projects (like writing a PhD thesis), because those can be broken up into multi-week or multi-month chunks.
Moreover, if these models can complete multi-week tasks in AI research engineering, then we’ll be very close to AI that can accelerate AI research.
Imagine if each human AI researcher suddenly had a team of 10 digital engineers who can autonomously complete multi-week projects. That could more than double the productivity of the field, and that could start a positive feedback loop.
Will the trend continue?
Whether this time horizon trend will continue seems like the most important question in forecasting AI today.
My bet would be that it’s more likely or not to continue until 2028.
That’s because I argue the fundamental drivers of AI progress – investment into compute and algorithmic research – are set to continue to increase until at least 2028, meaning we should expect major AI progress over that time frame.
In particular, I expect many of these improvements will increase the time horizon over which AI models can act. For example, we’ll see:
Better multimodal base models, which will be better at visual perception (a major bottleneck to web agents currently).
Better reasoning models made on top of those, which will be better at planning, more situationally aware, better at sticking to goals etc.
Better agent scaffolding, making agents more reliable.
Reinforcement learning applied to current agents to make them more goal-directed.
Existing agents when deployed will generate data that can be used to train the next generation, creating a fly wheel.
There’s also a decent chance a new scaling paradigm is discovered. After all, human brains are pretty good at long horizon tasks without using much compute or data compared to AI models. That shows there are much better ways to build AI waiting to be discovered.
At some point, we could hit a threshold of reliability that lets the agents act indefinitely. After all, if an AI can do multi-month tasks, what skills is it lacking that prevents it from doing multi-year tasks?
As we approach this threshold, the trend line would start to curve upwards in an acceleration – which might have already started in 2024.
However, if transformative AGI isn’t reached by around 2030, scaling will start to slow.
What are the best reasons to be skeptical?
While the trend is compelling, there are legitimate reasons to question whether it will continue, or that it implies AGI soon.
First, while the tasks tested are much closer to real-world work than most benchmarks, they still need to be well-defined enough to use in a benchmark at all, for example, to have clearly defined success conditions.
To investigate the significance of this drawback, in the full paper METR roughly rated the tasks on how ‘messy’ they were. They found that the messier tasks were indeed harder for AIs (and none of the tasks were as ‘messy’ as something like doing novel research).
However, even among the messier tasks, they observed a similar rate of improvement over time. This suggests AI is still on track to tackle messy tasks, it’s just that it’ll take longer.

Similarly, the horizon was based on when tasks could be completed successfully half the time. If you require a higher chance of completion, the rate of improvement is again similar but lagged by a couple of years.
I expect something similar would be true of high-context tasks: they’re harder to AIs, but context lengths have been steadily expanding over time.
So, we could be in for a future where AI is able to do well-defined one-month tasks with a 50% success by 2030, but still can’t do messier, very high-context ones with higher reliability. Although that could lead to significant automation, human leaders would remain a crucial bottleneck.
Second, the date when AI models reach multi-week tasks is sensitive to the selection of tasks used in the benchmark. METR discussed this objection in their paper, and point out they’re focused on computer use tasks, which they’ve checked across a variety of benchmarks.
METR’s tasks were also been chosen to be especially relevant to automating AI research, which is the class of task that’s most of interest.
But it’s notable AI still can’t reliably do some computer tasks that take humans no time at all; while being able to easily complete tasks that take humans hours (or even decades). So, the notion of a single time horizon is a significant simplification.
Moreover, if we expanded beyond software engineering style computer use tasks, for instance to include robotic manipulation, or the ability to have novel research insights, we might find the trend shows these are still a very long way away.
Update July 2025: METR have subsequently released an expanded data set, finding similar rates of improvement in other domains.
Perhaps the most important objection is that reinforcement learning might work very well for 1-hour tasks, explaining recent progress, but stop working well at some longer horizon.
That’s because for longer horizon, messy, high-context tasks, it’s much harder to create a good reward signal. (It’s also much harder to create a good dataset for pretraining.)
So, maybe at some point in the next few years, this trend will hit a plateau.
In that scenario, we’ll have extremely smart AI assistants, but we won’t be near autonomous AI workers. That would be a pretty good outcome for humanity!
However, if there's one lesson from recent AI progress, it's this: don't bet against straight lines on a graph.
Learn more: METR’s announcement blog post, twitter thread, full paper.
This framing misses something critical about the nature of the modern workforce: the middle class—especially in knowledge work—functions as a semi-meritocratic pseudo-UBI. Most roles aren’t about raw productivity or essential output, but about maintaining a complex theater of coordination, compliance, and justification. Human tasks stretch across weeks not because the work takes that long, but because the system is designed around inefficiency as stability.
So when we talk about timelines to automation based on “task completion,” we’re already working off an abstraction that hides the real threat: AI doesn’t just do the tasks—it erodes the rationale for the structure around them.
And historically, over the last few business quarters, we've seen that these timelines keep arriving faster than expected. Surprising efficiencies, unexpected integrations, emergent behaviors—all pulling forecasts closer. The story of AI deployment isn't one of overhyping progress. It's one of consistently underestimating how quickly systems can collapse when their supporting illusions are exposed.
That graph is a blade, not a curve.
I’d also suggest we take really seriously how AI will impact jobs, arguably hurting most who are least prepared to adapt to an AI world:
https://open.substack.com/pub/garethmanning/p/high-tech-low-literacy-how-the-ai?r=m7oj5&utm_medium=ios